大模型多学到的,是小模型留不住的长尾信号
2026-06-09 · #paper
你在训练一个模型识别代码里的罕见错误。平时它看到的是变量命名、注释、常见语法模式。偶尔,十万个样本里才冒出一次跨文件状态污染。小模型那一刻好像记住了。过几轮常见样本一冲,又忘了。下次再遇到,它像第一次见。
旧路会说:小模型只是训练不够,多喂数据就行。论文说这句话只对一半。有些差距确实是样本效率:大模型先学会,小模型看更多数据也能追上。但还有一块差距是容量带来的。小模型在同一个混合数据里,被高频任务占满了表示空间。罕见任务每次刚挤进去,就被下一轮高频任务更新挤出来。
作者看到的入口很具体:大模型不是只会表达更多东西,而是更能把罕见信号留到下一次出现。高频任务在大模型里很快被安排好,后续梯度变弱,于是罕见任务的更新不再被反复覆盖。学习从一次次从头开始,变成可以慢慢累计。
翻译
在刚才那个罕见 bug 的例子里,这篇论文的方法像一个仓库分配问题。小仓库货架少,热门商品先占满位置。罕见零件进来时可以临时放一下,但下一车热门商品来了,它就被清掉。大仓库先把热门商品放稳,空出来的货架才够罕见零件长期待着。
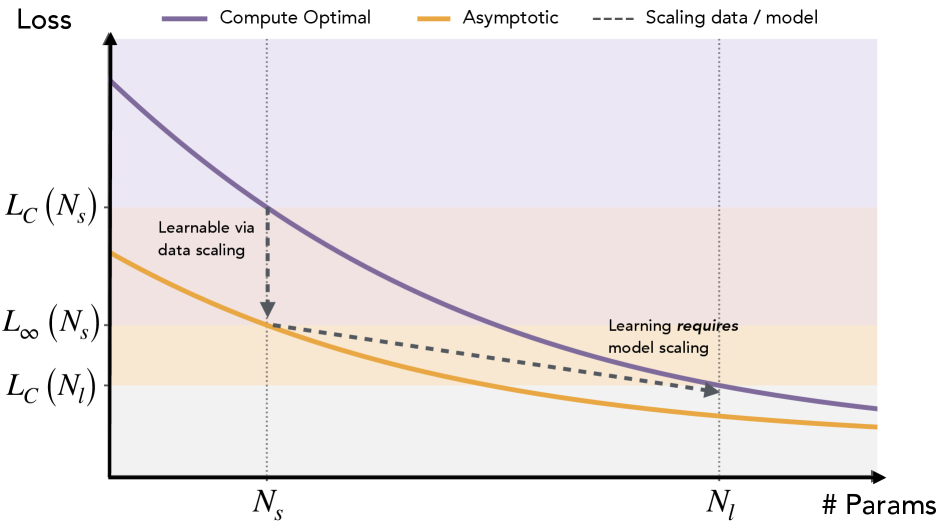
作者先用 scaling law 做了一个现象级判断。计算最优训练下,模型损失会随参数量下降;如果给小模型无限数据,它也会继续变好。但经验指数暗示一种情况:大模型在有限训练下达到的某些损失,小模型即使走向无限数据也到不了。作者把前一种差距叫 data scaling 可以补上的差距,把后一种叫必须 model scaling 才能补上的差距。这个推理本身不是完整定理,作者也承认它是 phenomenological。它的作用是把问题钉住:大模型到底多学了数据分布里的哪一块?
于是他们做了一个干净的玩具世界。数据由很多线性回归任务混在一起。每个任务有频率,也有复杂度。任务越常见,出现概率越高;任务越复杂,需要的特征方向越多。学生模型只有一个共享编码器,宽度 N 就是它能保留多少个方向。
这时候你看,学习顺序变得很简单:模型保留的不是任务,而是特征。每个特征有一个效用:
utility = task frequency * feature strength
宽度为 N 的模型,会保留效用最高的 N 个特征。高频任务的特征效用高,简单任务的头部特征效用也高。低频又复杂的任务,很多特征排在队伍后面。小模型轮不到它,大模型才轮得到它。
但这还没解释最关键的事:罕见任务很久才出现一次。模型上次见到它时更新了一点,下一次出现前,这点更新会不会被冲掉?论文的第二步就在这里。
作者证明,高频任务的梯度只来自模型还没解释掉的那部分残差。小模型解释不完高频任务,所以高频任务一直用强梯度拉它。罕见任务刚写进去,就被拉走。大模型先把高频任务解释得差不多,残差小,梯度弱,罕见任务的方向就能稳定下来。
可以把机制压成这样:
小模型:罕见样本出现 -> 临时学到 -> 高频梯度覆盖 -> 下次从头学
大模型:罕见样本出现 -> 保留一部分 -> 下次接着学 -> 慢慢形成结构
这不是只在玩具模型里好看。作者又把任务注入 OLMo 预训练。模型从 4M 到 4B 参数,语料是 Dolma v1.7,训练最多 210B tokens。他们构造两个三 token 任务:TCMP 比较两个 token 背后的顺序,TADD 做 modular addition。每个任务 10K 个实例,训练测试各半,注入频率从每个 batch 约 1K 个实例,一直到每 10 个 batch 才 1 个实例。
结果和玩具模型对上了。频率高时,小模型也能学;频率低时,只有大模型能学到并泛化。更重要的是,作者看了模型内部:大模型更早编码 TCMP 所需的全局 token 顺序特征,TADD 里也出现更多 Fourier modes。梯度分析也指向同一件事:在注入步,1B 模型的 batch gradient 更贴近任务方向;非任务 token 的梯度几乎和任务方向正交。20M 模型里,非任务梯度会随机撞到任务方向,干扰大得多。
这篇论文真正想说的不是大就是好。它说的是,在朴素混合预训练里,模型大小会改变长尾任务的学习动力学。小模型可能有表达某个任务的能力,但在混合数据里留不住那个任务。大模型的优势,是让罕见信号从一次性痕迹变成可累计的记忆。
核心概念
特征效用。 这东西就是一个特征在混合训练里值不值得占一个位置。它等于任务频率乘以这个特征自身强度。回到罕见 bug 的例子,常见语法模式出现频率高,所以它们的效用排前面。跨文件状态污染虽然重要,但出现太少,效用低。少了这个概念,就只能笼统说大模型容量大;有了它,才知道容量优先买到什么。
梯度干扰。 这是高频任务更新把罕见任务更新抹掉的过程。小模型还没把常见任务解释干净,所以常见任务每次都用强梯度改同一批参数。罕见 bug 的信号刚写进去,下一批常见代码就把那块表示拿走。少了这个概念,无法解释为什么罕见任务看过很多次仍然学不会。
罕见任务保留。 这不是记住训练样本那么简单,而是把上一次罕见样本带来的方向留到下一次。论文里 matched-frequency injection 很关键:总频率一样,只改变间隔。间隔越大,任务越难学,说明能不能跨 batch 留住信号本身就是瓶颈。少了这个概念,就会误以为只要总样本数够了就行。
洞见
大模型的一个真实优势,是把长尾信号从短暂噪声变成可累计的学习材料。
这句话能从论文里抽出来单独用。很多能力看起来像突然涌现,其实可能是以前每次都出现过,只是小模型每次都留不住。规模让高频任务不再占满全部更新通道,低频任务才开始在训练历史里留下连续痕迹。
博导审稿
选题眼光很好。大模型为什么能学到小模型学不到的东西,这个问题本身重要,而且作者没有停在表达能力或样本效率这种老答案上,而是把数据频率、任务复杂度、梯度干扰和记忆保留连成了一条机制链。
方法成熟度中上。玩具模型很干净,线性回归混合任务、正交特征块、共享瓶颈编码器,让特征效用和容量竞争可以解析出来。OLMo 注入任务也认真,不只看 loss,还看测试泛化、内部表征和梯度方向。它的短板也清楚:玩具模型离真实 Transformer 还有距离,TCMP 和 TADD 是人工任务,证明的是一个重要机制,而不是所有涌现能力的统一理论。
实验诚意足够。matched-frequency injection 很关键,因为它把总频率和出现间隔拆开了。表征分析用 DAS 和 PCA,梯度分析拆 task token 与 non-task token,也比只画 loss 更可信。但我会追问几件事:不同规模是否都用了最合适的训练超参;4M 模型深度不同会不会混入结构差异;人工注入任务替换序列开头 token,会不会带来位置或格式 artifact;多随机种子的鲁棒性还可以更强。
写作清楚,主线顺。第 2 节从 scaling law 推到 distribution 的某部分需要 model scaling,有启发性,但严格性弱。作者称它为 phenomenological 是诚实的,正文里仍需要控制语气。真实 LLM 里 complexity 很难定义,所以 OLMo 部分主要验证 frequency,而不是完整验证 frequency 加 complexity。
判决:weak accept 到 strong accept 之间,更靠 strong accept。理由是问题重要,机制清楚,理论和真实预训练实验互相咬合;但结论应限在受控混合训练与注入任务场景,外推到所有 agent 能力时要谨慎。
启发
对汉松当前关心的 AI coding 和 agent workflow,最直接的迁移是:别只问模型会不会某个能力,要问这个能力在训练和使用链路里出现得够不够密、间隔会不会太长、有没有机制把上次经验留到下次。很多 agent 能力,比如命令行恢复、跨文件调试、长任务规划,在普通语料里就是低频复杂任务。小模型可能不是完全做不到,而是在通用训练里没机会稳定保留。
可以把这个机制接到数据和训练设计上。如果要强化某个能力,单纯扩大通用数据可能很浪费。更有效的杠杆是提高目标任务频率,设计课程,做 replay,缩短关键能力样本之间的间隔,或者在 post-training 里反复把同一类能力拉出来练。论文甚至暗示:提高目标任务频率,某些时候可能比扩大模型更便宜。
它也反过来提醒评测方式。平均 loss 会掩盖长尾能力。应该单独看低频任务、复杂任务、跨轮保留能力。对 agent 来说,评测不要只看一次任务是否成功,还要看经历过一次失败或修复后,下次同类任务是否更快、更稳。
原文核验
本次采用 PDF-first 流程。PDF 来源为 https://arxiv.org/pdf/2605.29548,HTTP 状态 200,content-type 为 application/pdf,文件头为 %PDF,文件大小 5,180,151 bytes,共 37 页。PDF 已用 PyMuPDF 抽取全文,文本保存于 /tmp/ljg-paper-2605.29548/2605.29548.txt,总字符数 120,716,总行数 2,920。
首页覆盖标题、作者、机构、摘要与 Introduction 开头。尾部覆盖 Appendix F.2 的 compute-optimal comparison,并覆盖 References 与 Appendix A-F。论文有 appendix,已被抽取到文本末尾。overview 图采用 arXiv HTML 版 Figure 1,图片 URL 为 https://arxiv.org/html/2605.29548v2/x1.png,已保存到 Paper Notes/images/20260609T121352--paper-larger-models-rare-task-retention-overview.png。正文阅读主要基于 PDF 抽取文本,HTML 只用于提取 Figure 1 图片。